Troubleshooting:Shapefile 乱码与字符截断问题
Shapefile是上个世纪90年代的数据格式,但是由于它开放易用至今仍然倍受欢迎,最近与shapefile编码相关的问题此起彼伏连绵不绝,整理下几个高频问题共享之。
为什么我的shapefile在ArcGIS 10.3中打开乱码?
原因
这个问题的根本原因就是读取文件使用的编码类型和文件实际存储的编码类型不一致。
Shapefile文件的头文件(dBase Header)中,一般会包含shapefile使用的编码类型的信息,这个信息成为 LDID ( Language Driver ID),这样在使用应用程序打开 shapefile 的时候,应用程序就知道用何种编码类型去正确读取它,而不会发生乱码。 在 ArcGIS Desktop 生产的 shapefile 数据中通常会包含这项信息。在Shapefile的子文件中,有时我们还会发现同名 ***.cpg** 文件,文件中也存储了编码信息,用记事本打开,看到例如 utf-8。
二者被ArcGIS 识别的优先顺序是,LDID 优先于 CPG文件。也就是如果头文件中没有约定读shapefile的编码类型时,如果这时刚好有个CPG文件,那么ArcGIS就会使用这里的编码类型读取。
我们知道 shapefile 是个开放格式,只要你了解了数据规范,完全可以脱离ArcGIS自己生产出来。在Windows中文语言设置下,假设你自己写代码或者使用第三方的程序生产了shapefile,例如MapGIS,默认使用 CP936(GBK)编码存储,但是无论粗心大意还是有意为之没有在数据头文件中约定“我用了936!”。如果是 ArcGIS 10.2 和之前的版本,那么没问题,ArcGIS 默认就是以这种方式识别,没有乱码。可是拿到 ArcGIS 10.2.1 ,ArcGIS 10.2.2,ArcGIS 10.3.x 这几个版本中发现乱!码!了!在缺失 LDID 和 CPG时,这几个版本默认使用 UTF-8 来读取 shapefile,这样必然乱码了。
解决方法
在shapefile子文件旁边创建个记事本,修改为同名的CPG文件,文本内容oem或者936。
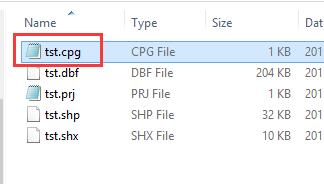
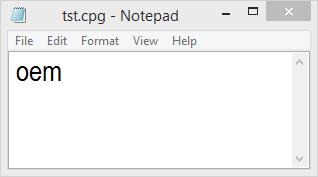
这样 ArcGIS 10.2.1 、10.2.10.3.x 在读取的时候,就知道你的数据是这种编码类型存储的,从而按照正确的方式读取。
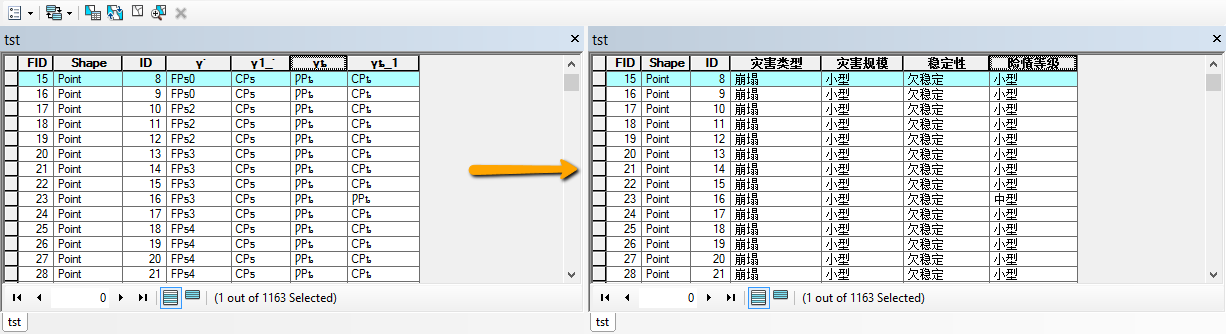
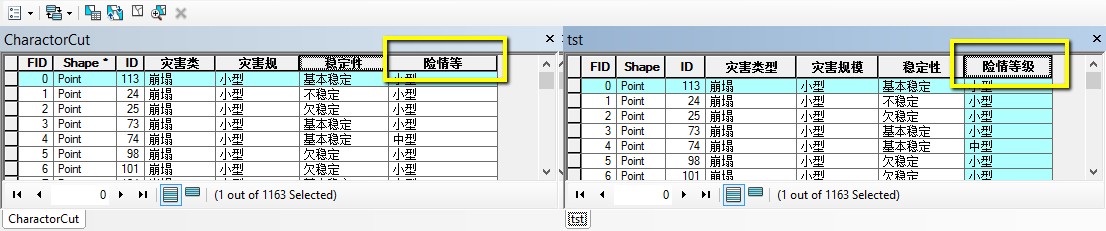
为什么ArcGIS 10.3导出 Shapefile的字段名会被截断成3个汉字?低版本中不是至少可以存储4个汉字吗?
原因
这个问题仍然与编码类型有关。
ArcGIS 10.2 以及更早的版本,ArcGIS写shapefile的时候,遇到中文默认使用Windows当前语言 字符集编码(也称 代码页/CodePage/OEM CodePage),例如中文一般使用的是 **CodePage 936(GBK)**。
ArcGIS 10.2.1 以及之后的版本,ArcGIS写shapefile的时候,默认使用的是 UTF-8 编码类型。
这两种编码类型存储汉字所使用的字节数是不相同的,上面的关键字中我也给出了 wiki 的链接,有兴趣点进去看看详情。简言之,shapefile自身的限制是字段为9个字节,CP936编码下汉字通常为双字节存储,因此可以存储 9/2=4 个汉字;UTF-8 编码下汉字至少需要3个字节存储,因此最多只能存储 9/3=3 个汉字了。
举个例子,在Python命令行中,我们求一下 Unicode字符串的长度就可以真相大白。
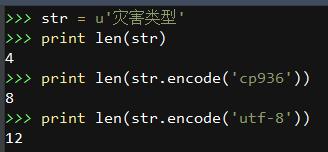
解决方法
Perfect Solution
使用地理数据库,放弃shapefile,避免各种截断问题,这也是存储地理数据的康庄大道。
但是,shapefile的拥趸说“我的需求是恢复以前存储4个汉字的shapefile,我不想用地理数据库,我希望得到老版本的shapefile的结果,我不在乎shapefile的编码类型是什么 ……bla bla……”好吧,方法还是有的。
Workaround
这里还有个注意事项:
如果你用的刚好是 10.2.1 和10.2.2 这两个版本,那么要打补丁后以下设置才生效。以前写过另外一篇,详情点 **这里**。
如果你用的是 10.3.x ,那么直接向下进行。
- 打开注册表,定位到 ‘My Computer\HKEY_CURRENT_USER\Software\ESRI\Desktop 10.x‘
- 创建项 ‘Common‘, 接着在其下创建 ‘CodePage‘ 项, 添加 ‘字符串’,名称: dbfDefault,健值:oem(或者 936)。
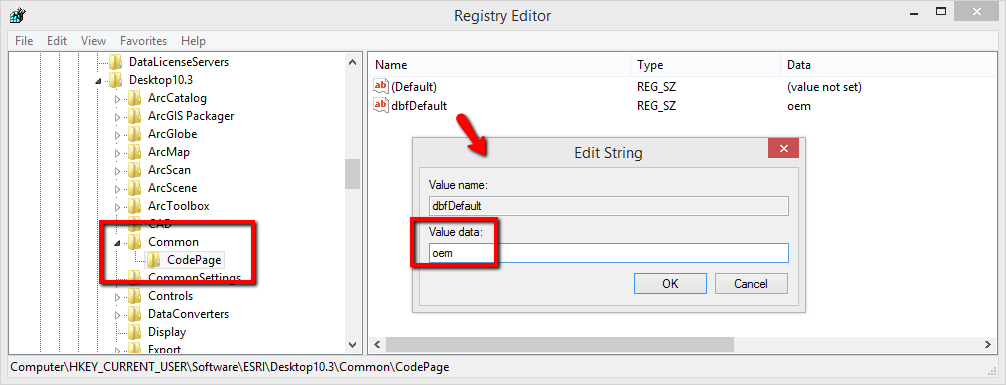
这样ArcGIS Desktop 读、写 shapefile的默认方式就将是Windows当前语言 OEM CodePage 936。
PS:
当然这种方法,也可以解决第一个问题,并且不需要为缺失oem编码信息的数据增加cpg文件了。两种方法,任君选择。
我如何检测当前shapefile使用了什么编码类型?
shapfile本身是个开放格式,当然我们有很多种途径查看shapefile的内部,读者中不乏代码大牛,只要了解数据规范应该方法多多。
我这里就分享一种通过 python 查看编码类型的简单的方法,使用python中的 struct模块 可以处理二进制数据,从而探测下 shapefile 的子文件 dbf 的头文件中的 LDID 信息是什么。
python代码示例
1 | #-*-coding:utf-8 -*- |
例如,得到这样的打印结果: (77, '0x4d') 通过这样的 ID 到 编码表 中查到就是 CodelPage 936。

当然如果有你更好的方法,博主求分享,可以直接在评论区里贴出来,共同讨论。
上面是三个最常被问到的问题,这三个问题通了,那么好多shapefile读写乱码问题就迎刃而解了。