ArcGIS中的影像分类
影像分类的目的就为了将图像中的像元划分成不同的类别,过程就是根据像元在不同波段的波普亮度、空间结构特征或者其他信息,按照某种规则或算法实现分类。遥感图像分类处理就是是为了提取遥感图像中的目标信息,遥感图像分类主要用于地物类别的区分。
影像分类分为监督分类和非监督分类,很多遥感书籍中都有这两种分类方法的比较。这里我结合ArcGIS软件简单整理一下:
监督分类
监督分类是使用被确认类别的样本像元去识别其他未知类别像元的过程。其中这些已被确认类别的像元就是训练样本。也就是说,在监督分类中,必须事先提取出代表总体特征的训练数据以及事先知道影像中有几种类别。这样就可以学习这些样本类别的先验知识,然后对整体数据进行分类。
在 ArcGIS 中,首先使用 Image Classification 工具条中的训练样本管理器,创建训练样本。
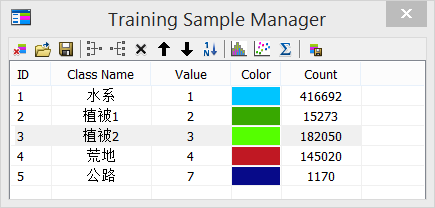

在创建样本之后,我们可以评估训练样本,使用直方图、散点图、统计数据。
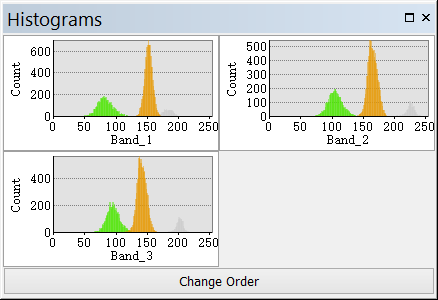
(1)直方图
打开直方图,每个波段对应一个直方图。不同类的直方图不应重叠。如果发生重叠,则需要删除或合并其中一些类。
直方图按钮仅用于整型影像,不适用于浮点型。
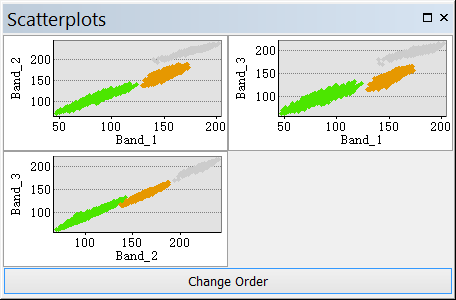
(2)散点图
散点图是参加分类的影像数据的波段的两两组合,如果有N个波段,就有1 + 2 + … + (N – 1) 个散点图。
对于所有波段组合,散点图和统计数据不应彼此重叠。
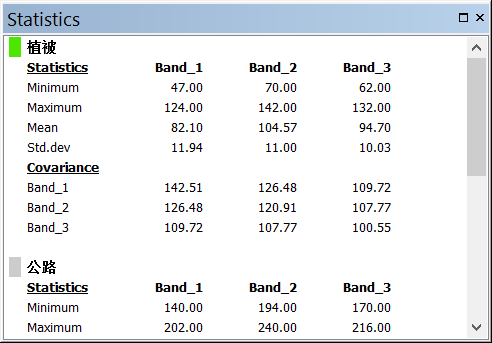
(3)统计数据
统计数据包括最小值、最大值、平均值、标准差和协方差矩阵。
创建训练样本后,可以使用交互式监督分类工具,探索性的直接查看分类结果。这个工具不需要事先创建特征文件,工具后台使用的是最大似然法分类方法。

在ArcGIS 中,监督分类的主要GP工具是 最大似然法分类工具(Maximum Likelihood Classification)。
(1)需要使用 特征文件(Signature File),既可以是通过训练样本制作的,也可以是ISO聚类工具求取,*.gsg文件。
(2)可以根据需要设置 剔除分数(Reject Fraction ),例如0.01。这样表示,正确分类的几率不到 1% 的像元就会成为 NoData。
(3)先验概率(priori probability),工具默认使用 Equal 先验概率,会给像元分配可能性最大的分类。但是,如果某些类出现的可能性大于(或小于)平均值,则应将 FILE 先验选项与输入先验概率文件结合使用。输入先验概率文件必须是包含两列的 ASCII 文件。左列中的值表示类 ID。右列中的值表示相应类的先验概率。类别先验概率的有效值必须大于或等于零。如果指定零作为概率,则类无法显示在输出栅格中。指定先验概率的总和必须小于或等于1。
(4)最大似然法分类工具还可以附带可选生成 置信栅格(confidence raster),这样可以了解每个像元的正确分类的概率。
非监督分类
非监督分类不预先确定类别,而是直接对相似的像元进行归类,根据归类的结果来确定类别。也就是在事先没有任何先验知识的情况下对未知类别的样本进行分类。当我们没有训练区,有对研究区不熟悉时,或者对图像中包含的目标物不明确的时候,采用此方法。
在 ArcGIS 中进行非监督分类,主要使用工具 ISO聚类非监督分类工具(Iso Cluster Unsupervised Classification)。
需要指定希望分出来的类别的数量,并且根据需要调整迭代的次数、类的最小尺寸、采样间隔。
ISO 是 iterative self-organizing 的缩写,也就是迭代自组织方法。此工具的工作原理从帮助中扒出来,供参考:
iso 聚类算法是一种迭代过程,用于在将各个候选像元指定给聚类时计算最小欧氏距离。该过程从处理软件指定的任意平均值开始,每个聚类一个任意平均值(您指定聚类数量)。将每个像元指定给最接近的平均值(多维属性空间中的所有平均值)。基于首次迭代后从属于每个聚类的像元的属性距离,重新计算各个聚类的新平均值。重复执行此过程:将各个像元指定给多维属性空间中最接近的平均值,然后基于迭代中像元的成员资格计算各个聚类的新平均值。您可通过迭代次数指定该过程的迭代次数。该值应该足够大,才能确保执行指定次数的迭代后,像元从一个聚类迁移至另一个聚类的次数最少;从而,使所有聚类变为稳定状态。迭代次数应该随着聚类数的增加而增加。