空间统计(二)分析模式 A
有时对于数据量较大的地理数据,我们希望通过一定的统计方法将空间模式量化,从而获知这些地理数据在空间上是聚合的、还是离散的、还是随机的等。

在了解如上工具之前,有一些空间统计学的基本知识还是要先搞明白,磨刀不误砍柴工,那就开始吧。
零假设、P值、Z得分、置信度
分析模式工具集中的工具都采用“推论统计学”,先确定一个零假设,也就是假设要素或与要素相关的值都表现为空间随机模式—— **Complete Spatial Randomness (CSR)**;然后再计算一个 p值,用来表示零假设的正确概率。分析模式工具集中的工具都会返回 P值(P-Value)和 Z得分(Z-Score),这是我们拒绝前面的零假设的依据,也就是我们观测的要素表现出显著性聚类或离散模式,而不是随机模式。
什么是 P 值? 什么是 Z 得分?
P值 就是概率值,它表示观测到的空间模式是由某随机过程创建而成的概率,或者我们简单的理解成是观测到的空间模式是随机空间模式的概率。P 值越小,也就是观测到的空间模式是随机空间模式的可能性越小,也就是我们越可以拒绝开始的零假设。
Z得分 表示标准差的倍数。例如,如果工具返回的 z 得分为 +2.5,我们就会说,结果是 2.5 倍标准差。如下所示,z 得分和 p 值都与标准正态分布相关联。
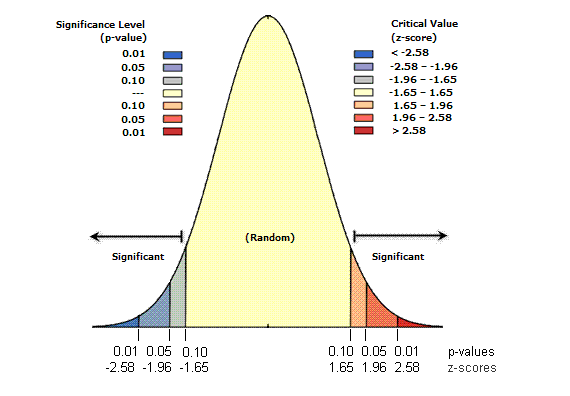
z 得分和 p 值结果是统计显著性的量度,用来判断是否拒绝零假设。在正态分布的两端出现非常高(正值)或非常低(负值)的 z 得分,这些得分与非常小的 p 值关联。当运行要素模式分析工具得到很小的 p 值以及绝对值很大的 z 得分时,就表明观测到的空间模式不太可能反映零假设中假定的随机模式。
那么,P值需要多小?或者说要小到什么程度,才能拒绝零假设呢?这时就需要我们自己主观选择一个 置信度(Confidence Level),典型的置信度有 90%、95%、99%。其中显见,99%的置信度是最保守的。
空间关系的概念化
空间统计分析和传统(非空间)统计分析的一个重要区别是空间统计分析将空间关系整合到算法中。在我们执行各种各样的空间统计工具时,需要选择一项“空间关系概念化”,如何选择就主要取决于要测量的对象。如下是常见的选项:
反距离、反距离平方(阻抗)
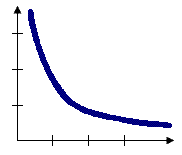
使用“反距离”选项时,空间关系的概念模型是一种阻抗或距离衰减。距离越远,影响越小。
INVERSE_DISTANCE:表示与远处的要素相比,附近的邻近要素对目标要素的计算的影响要大一些;INVERSE_DISTANCE_SQUARED:与 INVERSE_DISTANCE 类似,但它的坡度更明显,因此影响下降得更快,并且只有目标要素的最近邻域会对要素的计算产生重大影响。
例如:反欧氏距离适用于对连续数据(如温度变化)进行建模。再比如测量某种种子植物的聚集程度,使用反距离可能最合适。
距离范围(影响的范围)
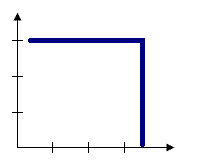
FIXED_DISTANCE_BAND:将对邻近要素环境中的每个要素进行分析。在指定临界距离内的邻近要素将分配值为 1 的权重,并对目标要素的计算产生重大影响。在指定临界距离外的邻近要素将分配值为零的权重,并且不会对目标要素的计算产生任何影响。
例如:要研究通勤模式并且已知平均上下班路程为 15 英里,则最好使用 15 英里的固定距离进行分析。
无差别的区域
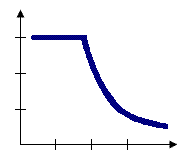
ZONE_OF_INDIFFERENCE:将“反距离”模型和“固定距离范围”模型合并为一体,在目标要素的指定临界距离内的要素将分配值为 1 的权重,并且会影响目标要素的计算。一旦超出该临界距离,权重就会随距离的增加而减小。
举个常见的例子,工作日的午饭我们通常会在公司附近解决,选餐馆的时候,可能在500米以内哪家都行,超过500米就可能太过占用时间从而影响中午的休息、娱乐等等,当餐馆距离公司超过500米,随着距离的增加,权重就不断减小。
面邻接(一阶)
对于面要素类,可选择 CONTIGUITY_EDGES_ONLY或 CONTIGUITY_EDGES_CORNERS。其中,CONTIGUITY_EDGES_ONLY:只有共用边界的相邻面要素会影响目标面要素的计算,不共享边的面被排除在目标要素计算之外。CONTIGUITY_EDGES_CORNERS:共享边界、结点的面要素会影响目标面要素的计算。如果两个面存在重叠的部分,则将视为相邻要素并包含在彼此的计算中。
例如,研究某些传染病的传染区域时,可以考虑此空间关系概念化。
K最近邻域
K表示最近邻域数目。如果 K(邻域数)为 8,则距目标要素最近的 8 个邻域都会包含在该要素的计算中。在要素密度高的位置处,分析的空间范围会比较小。与此类似,要素密度稀的位置,分析的空间范围会比较大。使用生成空间权重矩阵工具时该方法可用。
通过文件获取空间权重(用户定义的空间关系)
GET_SPATIAL_WEIGHTS_FROM_FILE:将在空间权重文件(.SWM) 中定义空间关系,文件可以使用空间统计工具箱中其他相关的工具创建,这里先不展开,后面再说。
有了这些基础知识,我们就来看看ArcGIS Desktop 中提供的这些工具,有点长了,再另起一篇看工具吧。