空间统计(二)分析模式 B
Updated: 2017-10-11
修改了文中表意含糊的语句,增加了更多解释性描述。
这一篇具体看分析模式工具集中的具体工具,整理这一篇的目的,不是要读者了解每个工具的背后使用了多么高级的算法,运用了多么庞大的公式,而是一起了解这些工具究竟可以为我们研究什么样的空间数据分布模式,当需要探索数据的空间性质时,知道应该如何去应用这些分析工具。

Average Nearest Neighbor
平均最近邻工具,计算每个要素中心与其最邻近要素中心的距离,然后求取所有最近邻距离的平均值,然后用这个观测平均值与随机分布的期望平均值进行比较,从而可以反应数据的空间分布是聚合的还是分散的。
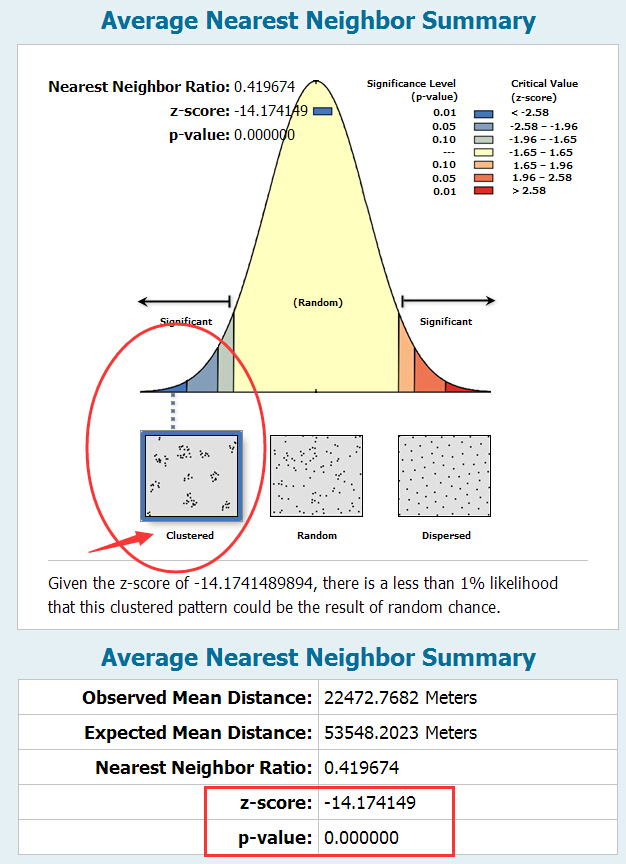
Average Nearest Neighbor 工具将返回五个值:
- 观测的平均距离 / Observed Mean Distance
- 期望的平均距离 / Excepted Mean Distance
- 最近邻指数 / Nearest Neighbor Ratio
- z得分 / z-score
- p值 / p-value
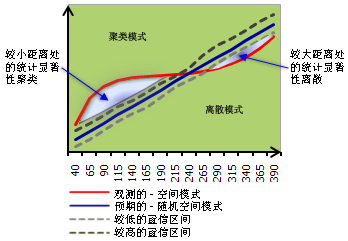
其中,最近邻指数是观测平均值与期望平均值的比率,最近邻如果最近邻比率小于1,则表现的模式为聚类。如果指数大于1,则表现的模式趋向于扩散。

在HTML报告文件中可以更显见的了解数据的趋势:
可能的应用:
- 评估竞争或领地:量化并比较固定研究区域中的多种植物种类或动物种类的空间分布;比较城市中不同类型的企业的平均最近邻距离。
- 监视随时间变化的更改:评估固定研究区域中一种类型的企业的空间聚类中随时间变化的更改。
- 将观测分布与控制分布进行比较:在木材分析中,如果给定全部可收获木材的分布,则您最好将已收获面积图案与可收获面积图案进行比较,以确定砍伐面积是否比期望面积更为聚类。
Spatial Autocorrelation
空间自相关 (Global Moran’s I) 工具同时根据要素位置和要素的属性值来度量空间自相关。在给定一组要素及相关属性的情况下,评估所表达的模式是聚类模式、离散模式还是随机模式。
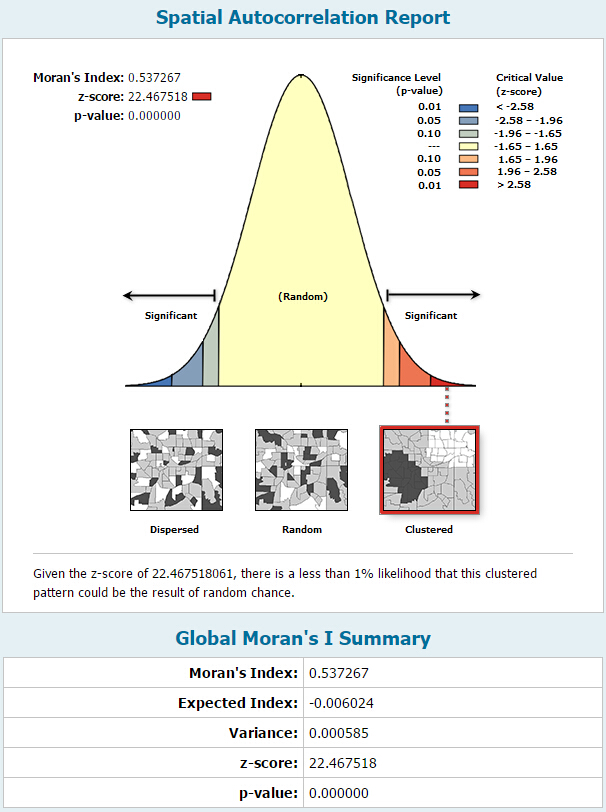
此工具将返回五个值:
- Moran’s I指数 / Moran’s I Index
- 预期指数 / Expected Index
- 方差 / Variance
- z得分 / z-score
- p值 / p-value
Moran’s I 指数:
Global Moran‘s I 工具计算所评估属性的均值/Mean和方差/Variance。然后,将每个要素值减去均值,从而得到与均值的偏差/Deviation。 将所有相邻要素(例如位于指定距离范围内的要素)的偏差值相乘,从而得到叉积/Cross Production。Global Moran’s I 统计量的分子是这些叉积的和。
如果数据在空间上趋于聚类,则Moran’s I指数为正值;如果空间上高值排斥其他高值而分散存在,则Moran’s I 指数为负值;如果叉积的正负值趋于平衡,则指数趋于0。
在使用这个工具的时候,注意以下几点:
- 输入要素的记录数至少30个,少于30结果不可靠。
- 选择的适当的概念化空间关系,具体根据自己的数据参考前一篇。
可能的应用
- 通过查找距离(即空间自相关最强的位置对应的距离),可为各种空间分析方法确定合适的邻近距离。
- 度量种族或民族分离随时间推移的总体趋势 - 分离程度是逐渐增强还是逐渐减弱?
- 总结某种观点、疾病或趋势随空间和时间变化的传播情况 - 观点、疾病或趋势是保持隔离和集中,还是传播开并变得更加分散?
Incremental Spatial Autocorrelation
增量自相关工具会去测量一系列的空间自相关,并且可以创建Z得分折线图。Z得分反映空间聚类的程度,峰值Z得分表示聚类最明显的距离。
这些峰值能做什么呢?我们可以将这些峰值作为其他工具(例如热点分析,将来会说到)的必要参数,例如距离范围,距离半径等等。
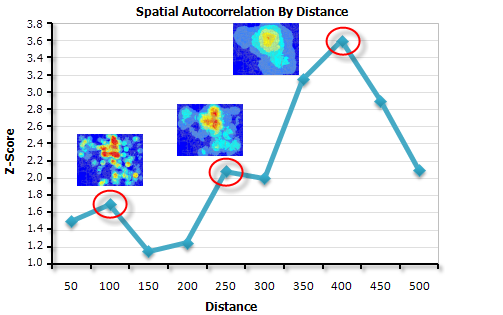
以下面的数据为例:
我欲研究下面几个城市的人口分布情况:

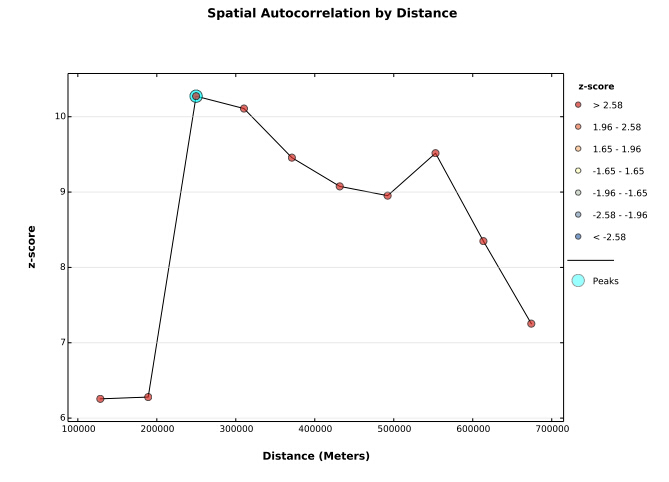

第一个峰值位于大约 250000 处。当显示多个具有统计显著性的峰值时(例如,本示例数据中有两个峰值),聚类在这些距离处均很明显。选择与感兴趣的分析比例对应的峰值距离,我们通常选择第一个具有统计显著性的峰值。
High/Low Clustering (Getis-Ord General G)
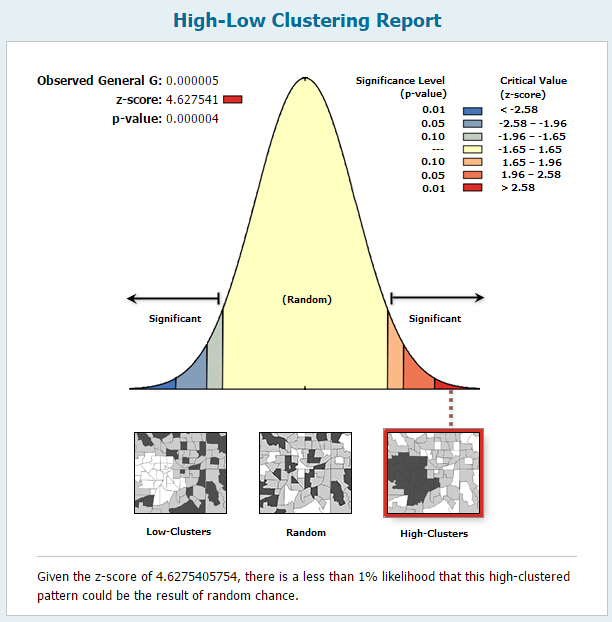
高/低聚类 (General G) 统计的零假设规定被研究的要素值不存在空间聚类。当返回的 p 值较小且在统计学上显著,则可以拒绝零假设。如果零假设被拒绝,则 z 得分的符号将变得十分重要。如果 z 得分值为正数,则观测的 General G 指数会比期望的 General G 指数要大一些,表明属性的高值将在研究区域中聚类。如果 z 得分值为负数,则观测的 General G 指数会比期望的 General G 指数要小一些,表明属性的低值将在研究区域中聚类。
当存在完全均匀分布的值并且要查找高值的异常空间峰值时,首选高/低聚类(Getis-Ord General G)工具。遗憾的是,高值和低值同时聚类时,它们倾向于彼此相互抵消。如果在高值和低值同时聚类时测量空间聚类,则使用空间自相关工具。
“高/低聚类”工具可返回五个值:General G 观测值、General G 期望值、方差、z 得分以及 p 值。
可能的应用:
- 在访问急症室的次数中查找出现的异常峰值,可能表明在局部或区域的健康问题的爆发。
- 比较在城市中不同种类零售业的空间模式,利用比较购物的方式来了解哪类行业充满竞争性(如汽车经销商)以及哪类行业拒绝竞争(如健康中心/健身房)。
- 汇总空间现象聚类的程度以检查不同时期或不同位置的变化。例如,众所周知的城市及其人口聚类。使用高/低聚类分析时,可以随时间来比较某个城市的人口聚类的程度(城镇发展以及密集度的分析)。
Multi-Distance Spatial Cluster Analysis (Ripley’s K Function)
基于 Ripley’s K 函数的多距离空间聚类分析工具是另外一种分析事件点数据的空间模式的方法。Ripley’s K 函数可表明要素质心的空间聚集或空间扩散在邻域大小发生变化时是如何变化的。
如果有兴趣研究要素的聚类/扩散如何相对于不同距离(不同的分析规模)进行变化,可以使用此工具。