空间统计(五)诊断回归分析结果
为了理解、解释、预测某个问题,我们会进行回归分析。上一篇中提到了回归模型中的因变量和解释变量的概念,用一组解释变量来建模解释因变量,但事实上,选择一组优质的解释变量并不是那么容易。通常我们会根据一些常识、理论基础、某些研究、专家的意见、参考文献等等选择一组解释变量,来进行解释变量的筛选。在ArcGIS Desktop中,当我们使用 普通最小二乘法(OLS)执行回归分析的时候,工具会进行诊断测试,提供一个汇总报告,帮助我们诊断回归分析的质量。这篇文章咱们就围绕这个话题展开——回归分析的结果诊断。
六项检查
> [帮助文档](http://resources.arcgis.com/en/help/main/10.2/index.html#//005p00000053000000)中也有相关的内容,但是觉得相对还是比较晦涩,我就结合Esri Global UC的视频介绍一下。内容不尽相同,但是对学习回归分析是有帮助的。
Check #1 解释变量与因变量具有预期的关系否?
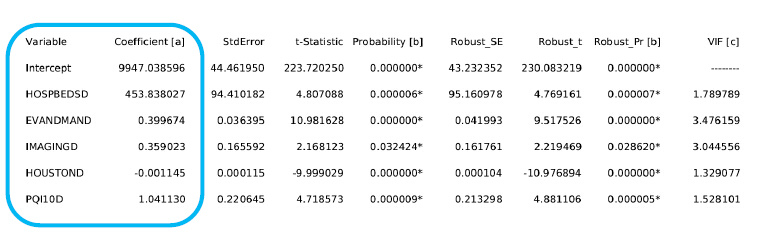
每个解释变量都会有一个系数,系数具有+/-号,来表示解释变量与因变量的关系。从工具的得到的报告中,我们看到的系数的正负,每个解释变量应该是我们期望的关系。如果有非常不符合逻辑的系数,我们就应该考虑剔除它了。
当然,有时也可能得到与常识不同的结论。举个例子,假如我们在研究森林火灾,我们通常认为降雨充沛的区域火灾的发生率会相对较低,也就是所谓的负相关,但是,这片森林火灾频发的原因可能是闪电雷击,这样降雨量这个解释变量可能就不是常识中的负相关的关系了。
因此,我们除了验证解释变量的系数与先验知识是否相符外,还有继续结合其他项检查继续诊断,从而得出更可靠的结论。
Check #2 解释变量对模型有帮助否?
解释变量对模型有无帮助说的就是解释变量是否有显著性,同样我们可以从 OLS 工具的汇总报表中得出些结论。
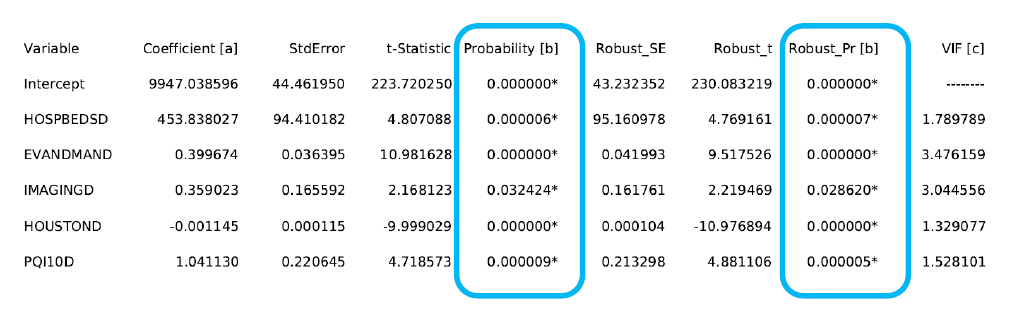
那如何了解这些解释变量是否有显著性呢?
OLS 工具除了对模型中的每个解释变量计算一个系数外,还执行统计检验以确定这些解释变量是否对模型有所帮助。
如果解释变量的系数为零(或非常接近零),我们认为这个解释变量对模型没有帮助,统计检验就用来计算系数为零的概率。如果统计检验返回一个小概率值(p 值),则表示系数为零的概率很小。如果概率小于 0.05,OLS 汇总报告上 概率(Probability) 旁边的一个 星号(*) 表示相关解释变量对模型非常重要。换句话说,其系数在 95% 置信度上具有统计显著性。
利用空间数据在研究区域内建模的关系存在差异是非常常见的,这些关系的特征就是不稳定。我们就需要通过 稳健概率(robust probability) 了解一个解释变量是否具有统计显著性。 OLS 汇总报告中所包括的另一项统计检验是用于不稳定性的 Koenker(Koenker 的标准化 Breusch-Pagan)统计量。
你也可以忽略上面说的,傻瓜方法就是:确保解释变量的概率、稳健概率列中带星号。
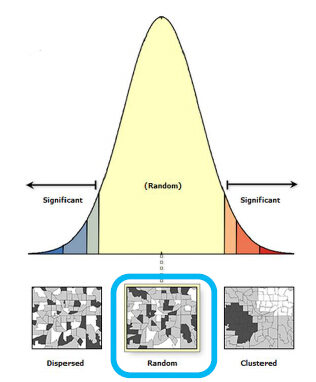
Check #3 残差是否有空间聚类?
残差在空间上应该是随机分布的,而不应该出现聚类。这项检查我们可以使用 空间自相关工具(Spatial Autocorrelation Tool)工具进行检查。
Check #4 模型是否出现了倾向性?
我们以前听过政治老师说过,不要戴着“有色眼镜”看人!也可能是历史老师?这不重要。。同样,回归分析模型中,也不要带有“成见”,不能具有倾向性,否则,这不是个客观合理的模型。
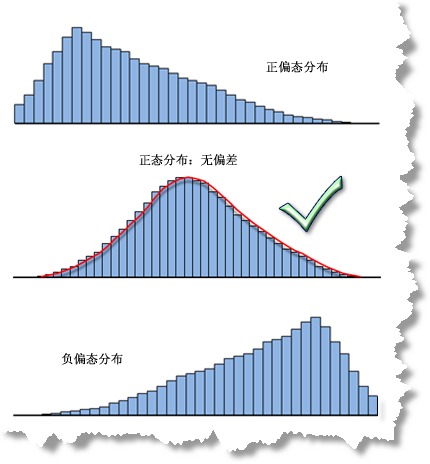
我们都知道正态分布是个极好的分布模式,如果我们正确的构建了回归分析模型,那么模型的残差会符合完美的正态分布,其图形为钟形曲线。
当模型出现偏差时,可能我们看到的图形也是诡异的,这样我们就无法完全信任所预测的结果。
如何检验呢?
在 OLS 汇总报告中,有一个具有统计显著性的 Jarque-Bera 诊断表示模型是否出现偏差。如下图中是没有偏差的模型,如果有偏差,在篮框中会出现星号。

因此,判断自己的模型没有偏差的最直观的方法就是:Jarque-Bera 诊断中没有星号。
解决偏差!
为了解决模型偏差,最好为所有模型变量创建一个散点图矩阵。因变量和一个解释变量之间存在非线性关系,这是出现模型偏差的常见原因。这些在散点图矩阵中看起来像一条曲线。
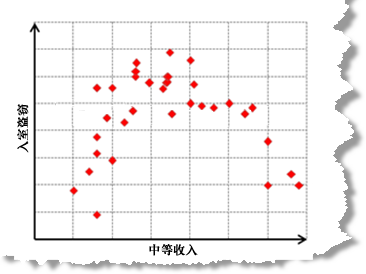
OLS 是一种线性回归方法,假设您正在建模的关系是线性关系。如果不是,可尝试变换您的变量,以查看这样做是否可创建出线性更明显的关系。常见变换包括对数变换和指数变换。
![]()
另外,散点矩阵图还可以显示出数据异常值。要了解一个异常值是否正在影响您的模型,请尝试在含有和不含有异常值的情况下分别运行 OLS,从而了解异常值对模型性能的更改程度,以及移除异常值是否会校正模型偏差。
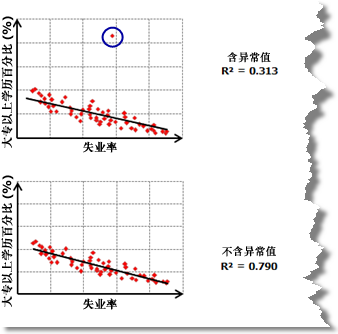
Check #5 解释变量中存在冗余吗?
在我们建模的过程中,应尽量去选择表示各个不同方面的解释变量,也就是尽量避免传达相同或相似信息的解释变量。要清楚,引入了冗余变量的模型是不足以信任的。
那么问题来了,如何判断是否存在冗余解释变量?
OLS工具会为每个变量计算膨胀因子(Variance Inflation Factor,VIF),VIF 值是对变量冗余度的一种度量,可辅助决定在不削弱模型解释能力的情况下可从中移除哪些变量。根据经验,VIF 值超过 7.5 就有问题。如果有两个或更多解释变量的 VIF 值超过了 7.5,应该一次移除其中一个变量并重新运行 OLS,直到冗余消失。记住,不要全部移除掉哦!
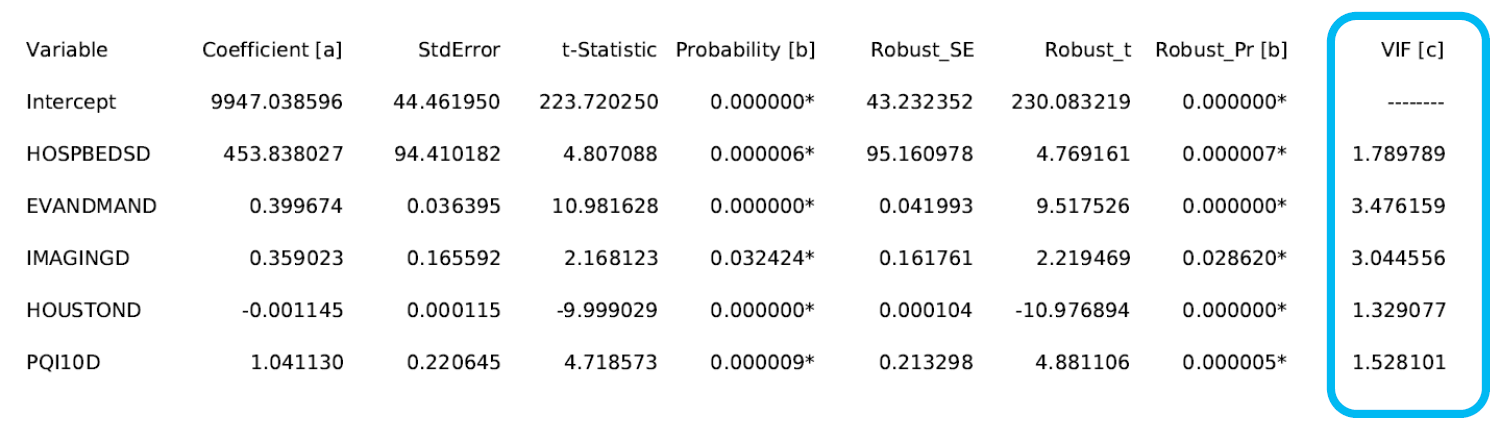
Check #6 评估模型的性能
最后需要做的是,评估模型的性能。 矫正R2值 是评估解释变量对因变量建模的重要度量。

这项检查应该放到最后。一旦我们通过了前面的所有检验,接下来就可以进行评估矫正R2值。
R2值的范围介于 0 和 1 之间,以百分比形式表示。假设正在为犯罪率建模,并找到一个通过之前所有五项检查的模型,其校正 R2 值为 0.65。这样就可以了解到模型中的解释变量说明犯罪率是 65%(更技术一些来说就是,模型解释了犯罪率因变量中 65% 的变化量)。在有些科学领域,能够解释复杂现象的 23% 就会让人兴奋不已。在其他领域,一个R2值可能需要更靠近 80% 或 90% 才能引起别人的注意。不管采用哪一种方式,校正 R2 值都会帮我们判断自己模型的性能。
另一项辅助评估模型性能的重要诊断是修正的 Akaike 信息准则 /Akaike’s information criterion (AICc)。AICc 值是用于比较多个模型的一项有用度量。例如,可能希望尝试用几组不同的解释变量为学生的分数建模。在一个模型中仅使用人口统计变量,而在另一个模型选择有关学校和教室的变量,如每位学生的支出和师生比。只要所有进行比较的模型的因变量(在本示例中为学生测试分数)相同,我们就可以使用来自每个模型的 AICc 值确定哪一个的表现更好。模型的 AICc 值越小,越适合观测的数据。
有关回归分析结果诊断就说这么多了,希望看起来不是那么枯燥无味……