空间统计(四)回归分析探索
在上一篇文章中,我提到的这些工具都是用于研究数据有什么样的空间模式,哪里聚类?哪里是热点?哪里有冷点?哪里有异常值?等等,总之研究的是“生米煮成熟饭”的结果状态。
而“空间关系建模”工具箱中的工具,更倾向于研究 Why? 例如,为什么会出现这种情况? 或者说什么导致了这种情况。这时我们就可以使用工具进行回归分析,如:普通最小二成法(OLS) 和 地理加权回归(GWR)。
你可能会问,为什么要进行回归分析?帮助文档中回归分析基础这一章写的最好,比较贴近读者,而不是冰冷的字典,我把回归分析的应用示例搬过来帮助理解,以下内容整理自帮助文档。
对某一现象建模,以更好地了解该现象并有可能基于对该现象的了解来影响政策的制定以及决定采取何种相应措施。基本目标是测量一个或多个变量的变化对另一变量变化的影响程度。示例:了解某些特定濒危鸟类的主要栖息地特征(例如:降水、食物源、植被、天敌),以协助通过立法来保护该物种。(更好地了解)
对某种现象建模以预测其他地点或其他时间的数值。基本目标是构建一个持续、准确的预测模型。示例:如果已知人口增长情况和典型的天气状况,那么明年的用电量将会是多少?( 建模预测)
您还可以使用回归分析来深入探索某些假设情况。假设您正在对住宅区的犯罪活动进行建模,以更好地了解犯罪活动并希望实施可能阻止犯罪活动的策略。开始分析时,您很可能有很多问题或想要检验的假设情况:( 探索检验假设)
- “破窗理论”表明公共财产的破坏(涂鸦、被毁坏的建筑物等)可招致其他犯罪行为。破坏财产行为与入室盗窃之间是否存在正关系?
- 非法使用毒品与盗窃行为之间存在某种关系吗(吸毒成瘾的人有可能通过偷取财物来维持他们吸毒的习惯吗)?
- 窃贼恃强凌弱吗?老人或女性户主家庭居多的住宅区内发生盗窃的可能性更高吗?
- 是住在富有的小区内更容易遭受盗窃,还是住在贫穷的小区内更容易遭受盗窃?
您可以通过回归分析来探索这些关系并解答您的问题。
总之,通过回归分析,我们可以对空间关系进行建模、检查和探究;回归分析还可帮助我们解释所观测到的空间模式背后的诸多因素。
在所有的回归方法中,OLS 最为著名。而且,它也是所有空间回归分析的正确起点。它可以尝试了解或预测(早逝/降雨)的变量或过程提供一个全局模型;而且,它可创建一个回归方程来表示该过程。地理加权回归 (GWR) 是若干空间回归方法中的一种,被越来越多地用于地理及其他学科。通过对数据集中的各要素拟合回归方程,GWR 为您要尝试了解/预测的变量或过程提供了一个局部模型。若使用得当,这些方法可提供强大且可靠的统计数据,以对线性关系进行检查和估计。
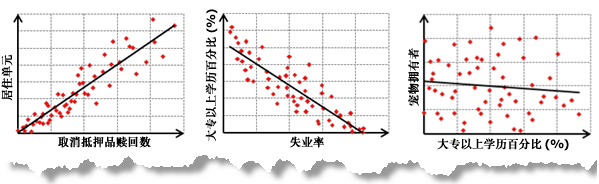
例如如下是两个变量之间存在正、负关系以及无关系的情况:
通过上文,我们有了对回归分析的基本的印象,下面我们就来深入进去,看看 回归分析是如何实现的?
回归分析是一个复杂的过程。在这个过程中,我们利用一个或多个解释变量对因变量进行最佳预测。说到底就是一个包含因变量、解释变量、系数、残差的数学公式,像下面的样子。

什么是因变量?
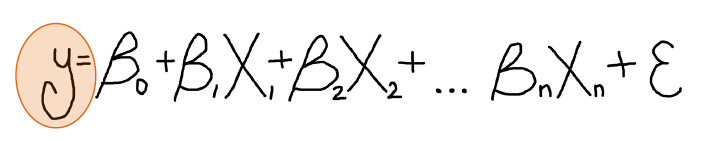
等式的左边是 因变量(Dependent Variable) ,记为 Y,表示我们要研究或者预测的对象。通常我们会先给定一些已知的 Y 值,用于构建回归方程,这些已知的 Y 值称为 观测值。
什么是解释变量?
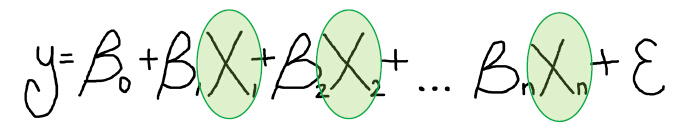
等式的右边的 X ,称为 自变量 或 解释变量(Explanatory Variables)。因变量是解释变量的函数。到这里,可能有的同学就晕了。
同样,举个栗子。我们想研究人们肥胖的诸多原因,想找到肥胖与收入、健康食品摄入、教育水平等等因素是否有关联。在这个例子中,肥胖就是因变量(Y),收入、健康食品摄入、教育水平等这些因素即为解释变量(X)。
还有重要的回归系数呢!
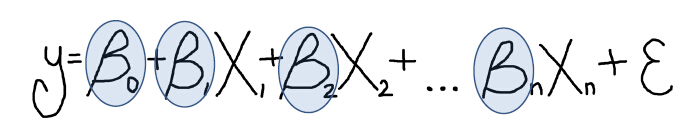
在方程中,我们还发现有些 β 值,称为 回归系数(Coefficient) 。表示解释变量与因变量之间的关系强度和类型,每个解释变量都有一个对应的回归系数。当关系为正时,关联系数的符号也为正。当关系为负时,关联系数的符号也为负。如果关系很强,则系数也相对较大。如果关系较弱,则关联系数接近于零。
其中,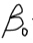 为回归截距(Intercept)。 它表示所有自变量(解释变量)均为零时因变量的预期值。
为回归截距(Intercept)。 它表示所有自变量(解释变量)均为零时因变量的预期值。
绝对不能忘记的残差!
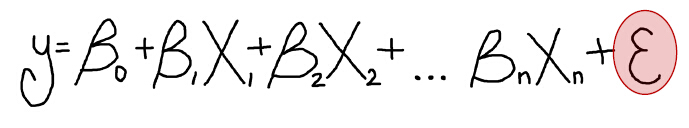
ε称为 残差(Residual)或 随机误差项,是因变量不能解释的部分。回归工具可以构造出能够对那些已知的 y 值作出最佳预测的方程。不过,预测值很少会和观测值完全匹配。y 的观测值与预测值之差称为残差。回归方程中的残差可用于确定模型的拟合程度。残差较大表明模型拟合效果较差。
回归模型的构建是一个迭代过程,在该过程中,需要找出有效的自变量来了解因变量,且需要运行回归工具来确定哪些变量为有效的预测因子,然后需要反复执行变量移除和/或添加操作,直到找出最佳的回归模型。
虽然构建模型的过程通常是探索性的,但它绝不是“盲目的搜查”。我们应通过了解相关理论、请教该领域内的专家并凭借一些常识性信息来确定可能的解释变量。在分析之前,我们应该清楚每个可能的解释变量和因变量之间的关系并能够对其正确与否作出判断,而且,对于这些关系不匹配的模型,我们应该表示质疑。