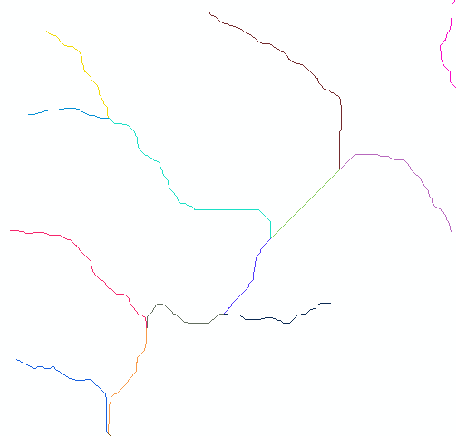
接收雨水的区域以及雨水到达出水口前所流经的网络被称为水系。流经水系的水流只是通常所说的水文循环的一个子集,水文循环还包括降雨、蒸发和地下水流。水文分析工具重点处理的是水在地表上的运动情况。“水文分析”工具用于为地表水流建立模型。

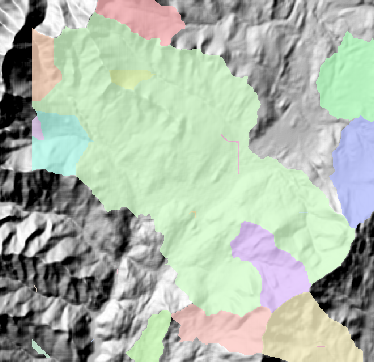
盆域分析(Basin):创建描绘所有流域盆地的栅格。
填洼(Fill):通过填充表面栅格中的汇来移除数据中的小缺陷。
流量(Flow Accumulation):创建每个像元累积流量的栅格。可选择性应用权重系数。
流向(Flow Direction):创建从每个像元到其最陡下坡相邻点的流向的栅格。
水流长度(Flow length):计算沿每个像元的流路径的上游(或下游)距离或加权距离。
汇(Sink):创建识别所有汇或内流水系区域的栅格。
捕捉倾泻点(Snap pour point):将倾泻点捕捉到指定范围内累积流量最大的像元。
河流连接(Stream link):向各交汇点之间的栅格线状网络的各部分分配唯一值。
河网分级(Stream Order):为表示线状网络分支的栅格线段指定数值顺序。
栅格河网矢量化(Stream to Feature):将表示线状网络的栅格转换为表示线状网络的要素。
分水岭(Watershed):确定栅格中一组像元之上的汇流区域。
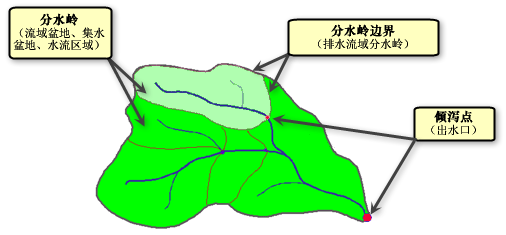
了解水系的术语,如下图:
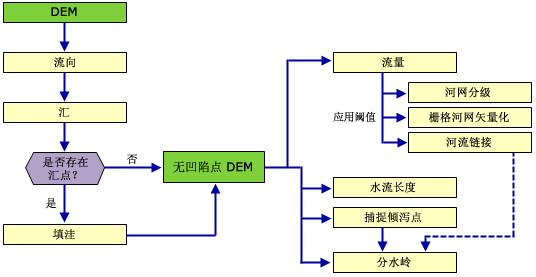
以下流程图显示的是从数字高程模型 (DEM) 中提取水文信息(如分水岭边界和河流网络)的过程:
现在就以手中的这个DEM为例来依次使用工具集中的工具,来学习这部分功能:
一、流向(Flow Direction)
流向工具的输出是值范围介于 1 到 255 之间的整型栅格。从中心出发的各个方向值为:
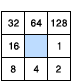
例如,如果最陡下降方向位于当前处理像元的左侧,则将该处理像元的流向编码将为 16。
如果像元的 z 值在多个方向上均发生相同变化,并且该像元是凹陷点的一部分,则该像元的流向将被视为未定义。此时,该像元在输出流向栅格中的值将为这些方向的总和。例如,如果 z 值向右(流向 = 1)和向下(流向 = 4)的变化相同,则该像元的流向为 1 + 4 = 5。可以使用汇工具将具有未定义流向的像元标记为凹陷点。

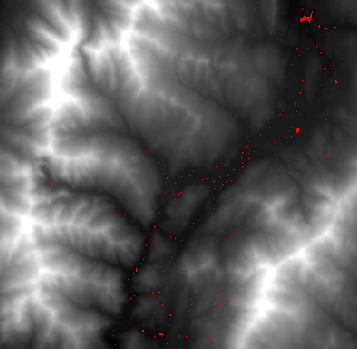
二、汇(Sink)
汇是指流向栅格中流向无法被赋予八个有效值之一的一个或一组空间连接像元。汇被视为具有未定义的流向,并被赋予等于其可能方向总和的值。
汇工具的输出是一个整型栅格,其中每个汇都被赋予一个唯一值。汇的编号介于 1 到汇的数量之间。
三、填洼(Fill)
通过填充表面栅格中的汇来移除数据中的小缺陷。
凹陷点是指具有未定义流域方向的像元;其周围的像元均高于它。倾泻点相对于凹陷点的汇流区域高程最低的边界像元。如果凹陷点中充满了水,则水将从该点倾泻出去。
TIPS:有关填充的Z限制
要填充的凹陷点与其倾泻点之间的最大高程差。如果凹陷点与其倾泻点之间的 z 值差大于 z 限制,则不会填充此凹陷点。
默认情况下将填充所有凹陷点(不考虑深度)。
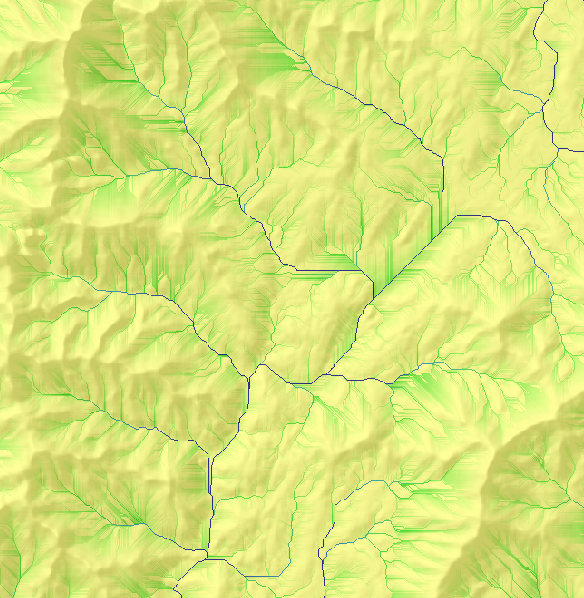
四、流量(Flow Accumulation)
创建每个像元累积流量的栅格。流量累积将基于流入输出栅格中每个像元的像元数。
高流量的输出像元是集中流动区域,可用于标识河道。流量为零的输出像元是局部地形高点,可用于识别山脊。
流量工具不遵循压缩环境设置。输出栅格将始终处于未压缩状态。
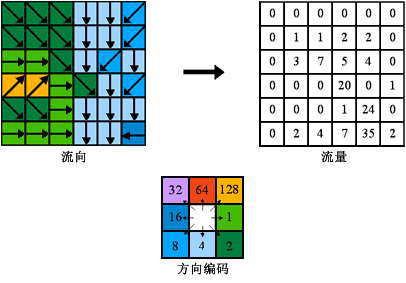
通过上面的填洼,求流向,得到如下流量图,看到了河道:
五、河网分级(Stream Order)
河网分级是一种将级别数分配给河流网络中的连接线的方法。此级别是一种根据支流数对河流类型进行识别和分类的方法。仅需知道河流的级别,即可推断出河流的某些特征。
河网分级工具有两种可用于分配级别的方法。这两种方法由 Strahler (1957) 和 Shreve (1966) 提出。在这两种方法中,始终将 1 级分配给上游河段。
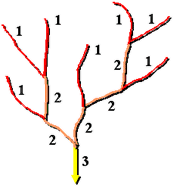
Strahler 河流分级方法:
在 Strahler 法中,所有没有支流的连接线都被分为 1 级,它们称为第一级别。当级别相同的河流交汇时,河网分级将升高。
因此,两条一级连接线相交会创建一条二级连接线,两条二级连接线相交会创建一条三级连接线,依此类推。但是,级别不同的两条连接线相交不会使级别升高。例如,一条一级连接线和一条二级连接线相交不会创建一条三级连接线,但会保留最高级连接线的级别。
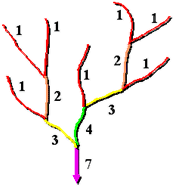
Shreve 河流分级方法:
Shreve 法考虑网络中的所有连接线。与 Strahler 法相同,所有外连接线都被分为 1 级。但对于 Shreve 法中的内连接线,级别是增加的。例如,两条一级连接线相交会创建一条二级连接线,一条一级连接线和一条二级连接线相交会创建一条三级连接线,而一条二级连接线和一条三级连接线相交则会创建一条五级连接线。
因为级别可增加,所以 Shreve 法中的数字有时指的是量级,而不是级别。在 Shreve 法中,连接线的量级是指上游连接线的数量。
六、栅格河网矢量化(Stream to Feature)
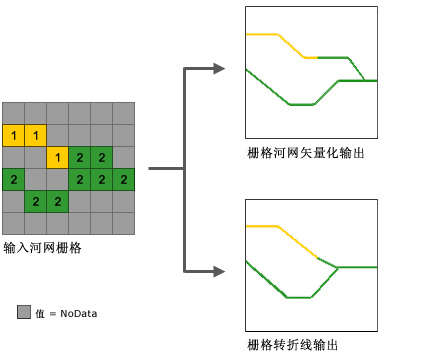
栅格河网矢量化工具使用的算法主要用于矢量化河流网络或任何表示方向已知的栅格线性网络的栅格。
该工具使用方向栅格来帮助矢量化相交像元和相邻像元。可将两个值相同的相邻栅格河网矢量化为两条平行线。
这与栅格转折线 (Raster to Polyline) 工具相反,后者通常更倾向于将线折叠在一起。下图是两者的对比:
七、河流连接(Stream link)
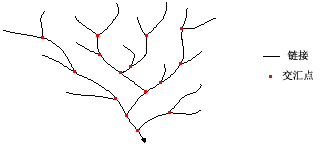
向各交汇点之间的栅格线状网络的各部分分配唯一值。
“连接”是指连接两个相邻交汇点、连接一个交汇点和出水口或连接一个交汇点和分水岭的河道的河段。
八、水流长度(Flow Length)
水流长度工具的主要用途是计算给定盆地内最长水流的长度。该度量值常用于计算盆地的聚集时间。这可使用 UPSTREAM 选项来完成。
该工具也可通过将权重栅格用作下坡运动的阻抗,来创建假设降雨和径流事件的距离-面积图。
九、捕捉倾泻点(Snap pour point)
捕捉倾泻点工具用于确保在使用分水岭工具描绘流域盆地时选择累积流量大的点。
捕捉倾泻点将在指定倾泻点周围的捕捉距离范围内搜索累积流量最大的像元,然后将倾泻点移动到该位置。
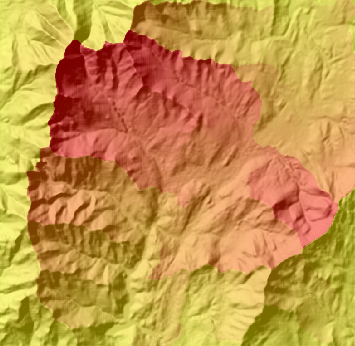
十、分水岭(Watershed)
确定栅格中一组像元之上的汇流区域。
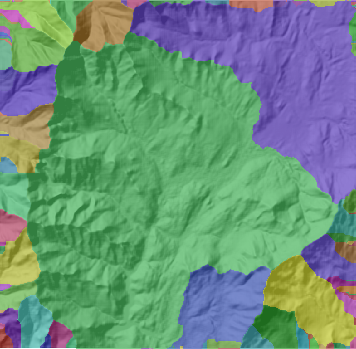
十一、盆域
创建描绘所有流域盆地的栅格。
通过识别盆地间的山脊线,在分析窗口中描绘流域盆地。通过分析输入流向栅格数据找出属于同一流域盆地的所有已连接像元组。通过定位窗口边缘的倾泻点(水将从栅格倾泻出的地方)及凹陷点,然后再识别每个倾泻点上的汇流区域,来创建流域盆地。这样就得到流域盆地的栅格。
以下是盆域分析示例:
That’s all.